
作为一个 3 月经验用了 3 年的半吊子前爬虫程序员,难免有在采集数据时不想写代码的时候,毕竟轮子天天造,requests.get 都写腻了写烦了。
而且相信很多做数据分析的同学,也不会为了搞一份临时的数据,就专门去学个爬虫。毕竟:
我就想写个爬虫,怎么要学那么多东西?
还好市面上有很多傻瓜式的数据采集器,不用写一行代码就能采集数据,这些数据采集器的使用体验到底如何呢?
州的先生就来给大家做一个不深不浅的测评,方便大家在不想写代码的时候,也能够顺利采集到数据。
火车头采集器
今天是第一个选手——火车头采集器。

据火车头官网的介绍:
火车采集器是目前使用人数最多的互联网数据抓取、处理、分析,挖掘软件。软件凭借其灵活 的配置与强大的性能领先国内数据采集类产品,并赢得众多用户的一致认可。
作为国内数据采集器的老前辈,这个自夸自擂还是有资格的。
我们首先到它的官网上下载最新的软件包:

然后安装完成就可以了。
要使用首先得进行登录,没辙,先去注册一个吧。之后顺利登录,就进入到了程序的主界面:

说实话,看到这个界面,我是有点懵的,这应该是一个专业级别的软件。
不行,看看它的使用手册先。
火车采集器是一个非常专业的数据抓取和数据处理软件,对软件使用者有较高的技术要求, 使用者要有基本的HTML基础,能看得懂网页源码,网页结构。同时如果用到web发布或数据库发布,则对自己文章系统及数据存储结构要非常了解。如果您相关基础薄弱,则需要花时间学习相关知识并多看使用手册,才可以掌握程序的使用.
按照手册的介绍,学习采集器时,如有以下相关知识,将会对程序的使用起到促进作用:
- html基础 了解网页的基本知识,帮助分析网页结构 http://www.w3school.com.cn/html/index.asp
- 正则表达式的使用 http://www.regexlab.com/zh/regref.htm
- Http协议的相关知识 Http请求抓包的方法 http://www.fiddler2.com/fiddler2/
- Access,Mysql,Sqlserver,Sqlite,Oracle,Mongo数据库的使用
- 代理服务器,FTP服务器相关知识
- 常见的SQL语句
- 插件需要PHP或C#编程功底的支持
- Apache或IIS服务器架设,网站的安装
得嘞,所需的计算机和编程知识还不少。
虽然不用写代码,但是也得会写代码呀。
再看看火车头采集器的任务新建窗口:
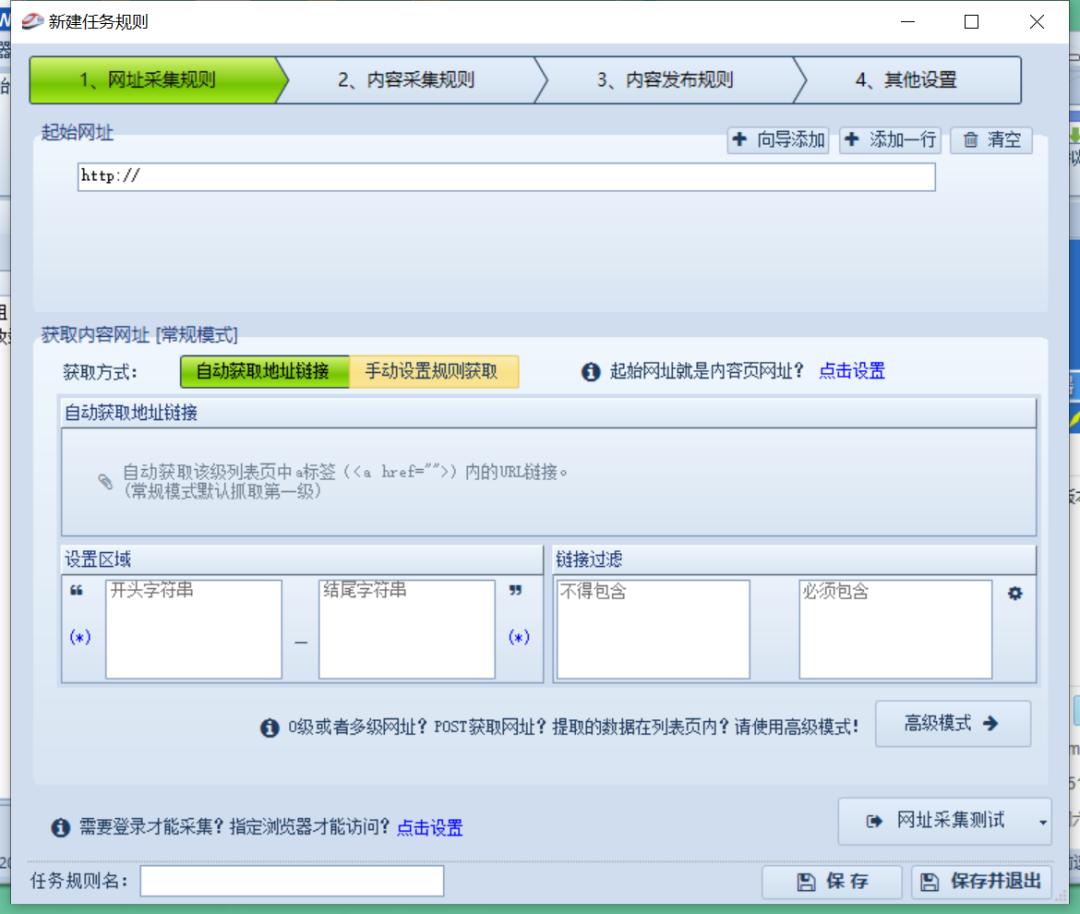
一共 4 个步骤,每个步骤都还有一大串的配置,感觉是相当的繁琐。
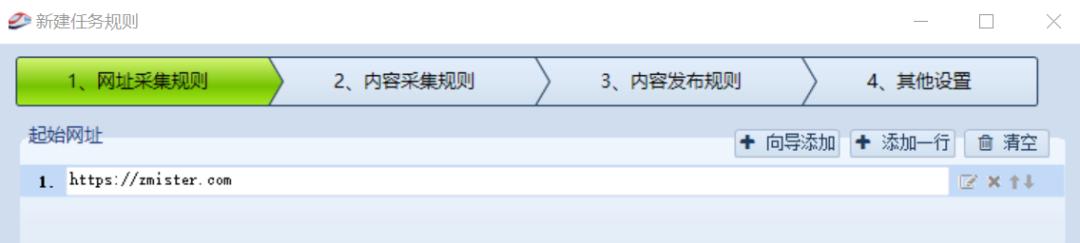
在这里,州的先生以采集「州的先生博客」为例来演示一下:
首先,配置采集的网址:
然后,内容采集规则我们也使用默认的:

内容发布规则,我们选择保存到本地CSV文件:

其他设置里面,主要用于配置代理、Cookie、线程等信息,我们都使用默认的。
输入任务名称之后,我们点击保存。程序主窗口的任务列表中就会出现我们刚刚新建的任务:
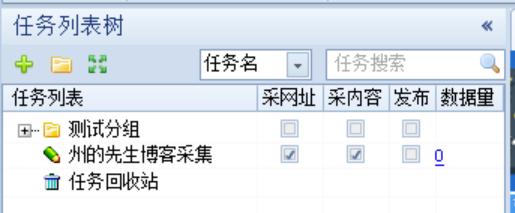
点击选中这个任务,然后鼠标右键选择「开始」以启动任务:
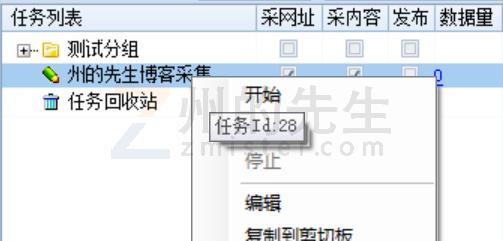
这样,我们的采集任务就已经开始了,在「运行管理」选项卡中可以看到任务运行的状态:
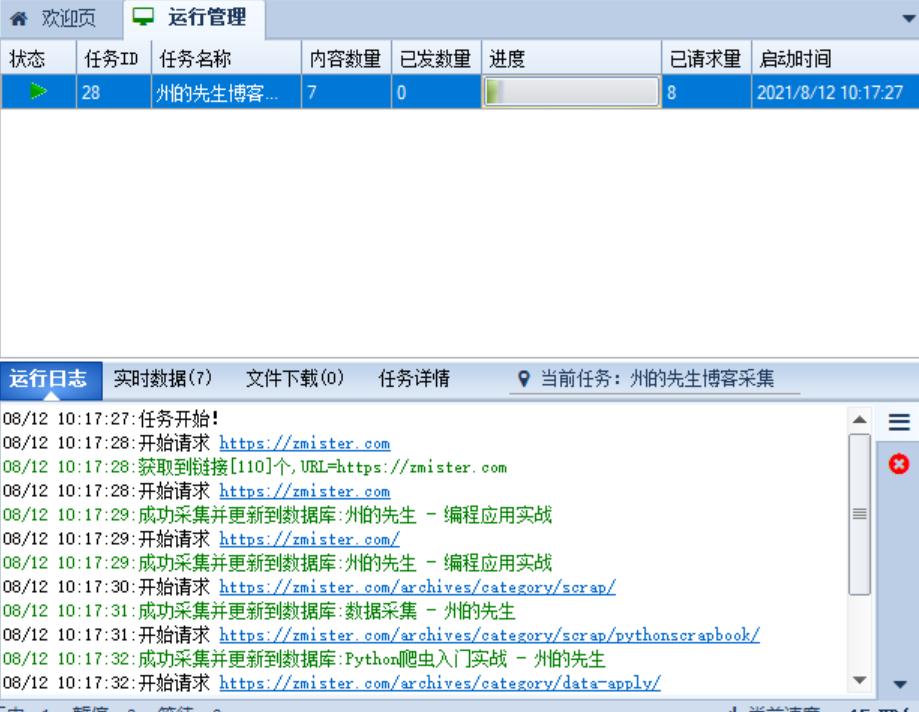
任务运行完成之后,可以看到程序采集的数据列表:
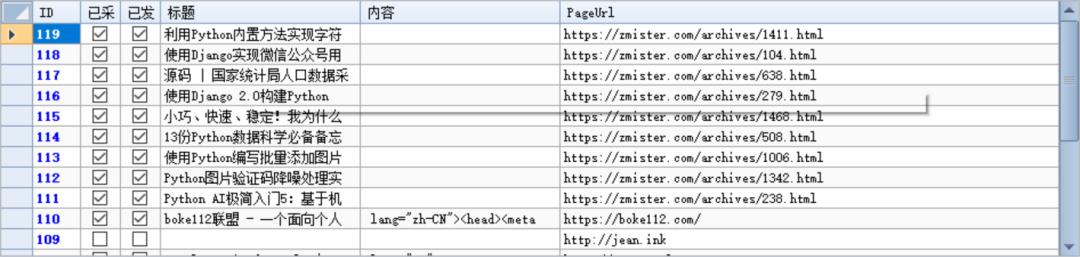
和数据内容:

虽然配置页面看起来很复杂,对于有数据采集经验的人来说,还是相对比较简单的,但是如果没有数据采集经验,操作起来就有点难度。
这种难度并非说是任务运行的难度,而是程序采集下来的数据与自己需求之间不匹配的难度。
八爪鱼采集器
下面再来看看另一个选手——八爪鱼。
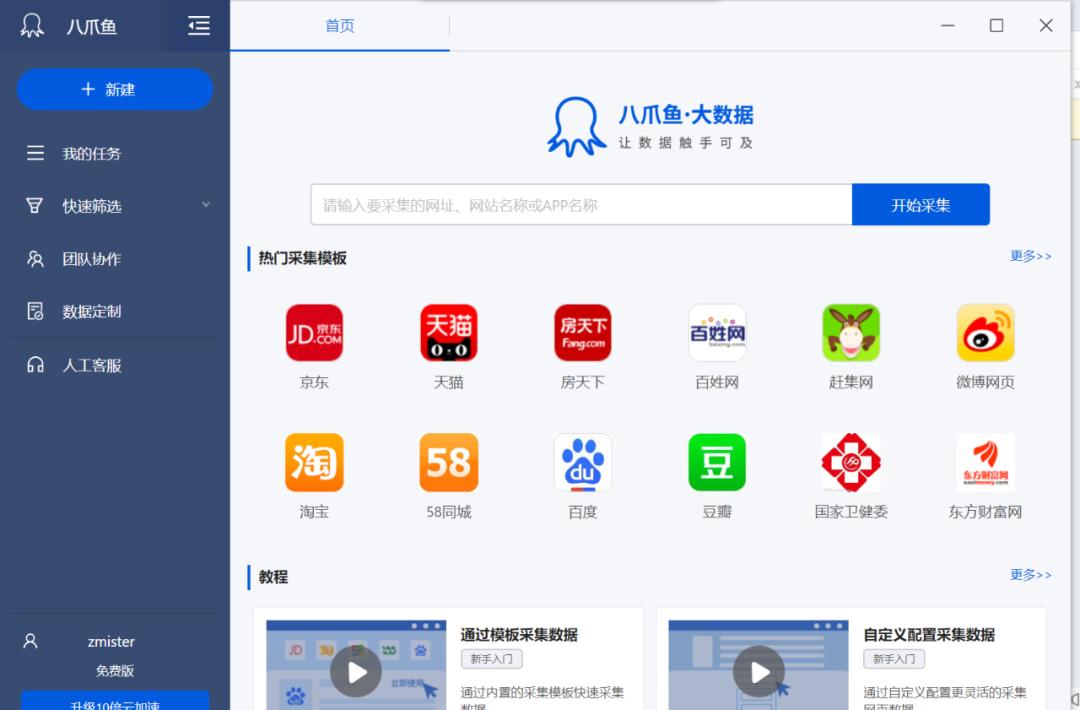
首页,界面就很互联网。而且主页还提供了很多模板,相当于直接使用这些模板就可以采集数据了。
不过,和上一个火车头一样,我们用州的先生博客来进行测试。
在输入框中输入州的先生博客的域名后,出现了一个按钮,提示网址已识别,可以直接进行采集。这简直也太方便了吧,那咱们来试试。
点击后跳转到了一个 WebView 的窗口,打开了州的先生博客:
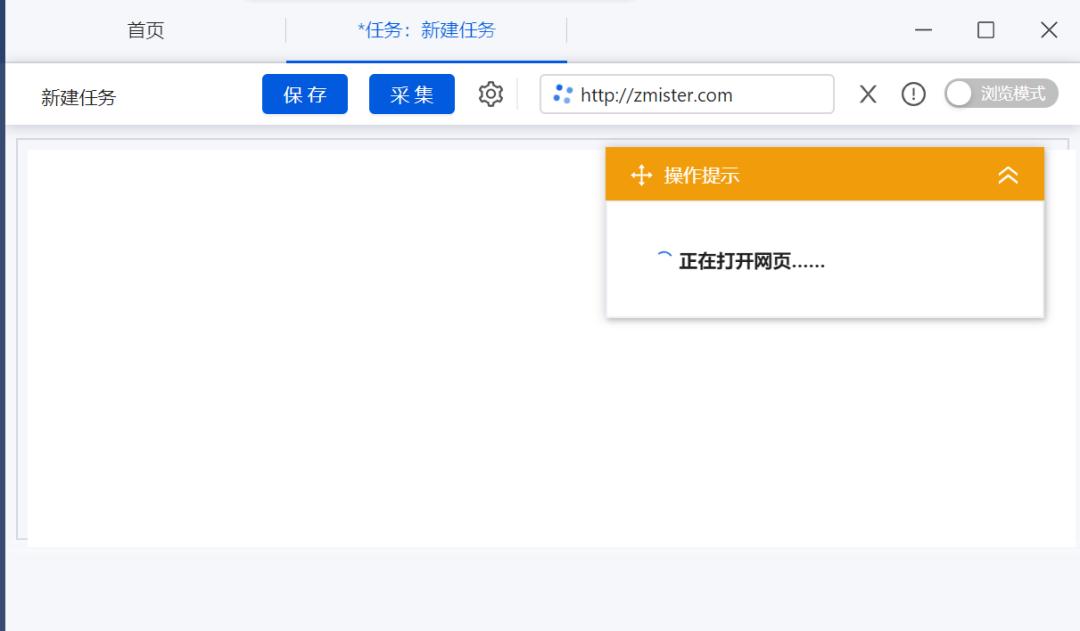
但是这加载也太慢了。
等了十来分钟,还没打开。罢了,不用博客做测试了。选择一个热门模板来试试吧:

来看看亿万爬虫都垂涎欲滴的淘宝数据:
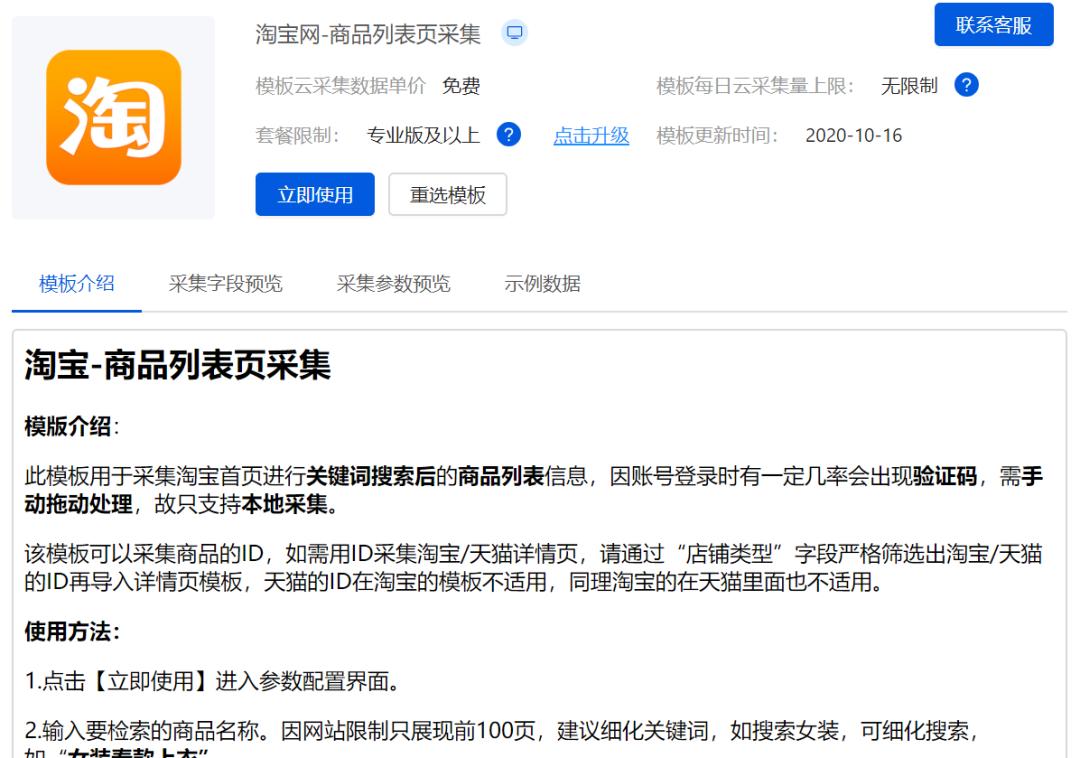
之前一直以为八爪鱼可以搞定淘宝的反爬验证,看来是我想多了。

而且免费用户还不能使用,罢了罢了。
换腾讯网来试试,输入网址后,打开的网页,然后自动下拉网页:
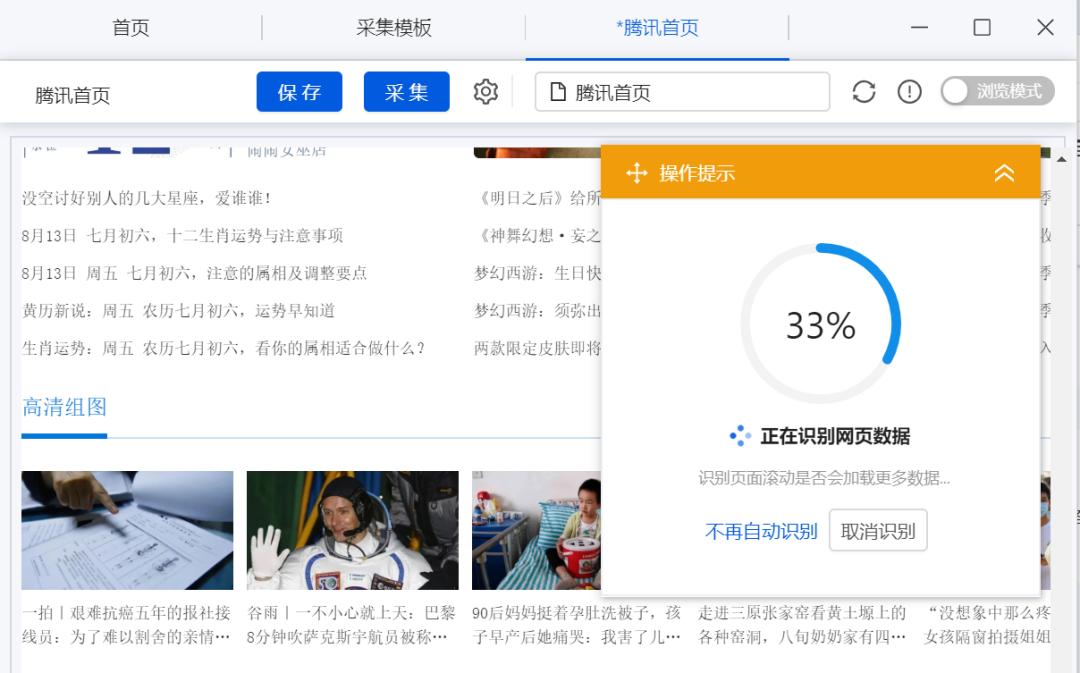
最终识别出了列表数据(但是不排除是八爪鱼后台服务器以模板的形式已经预置了腾讯网的采集和识别规则):
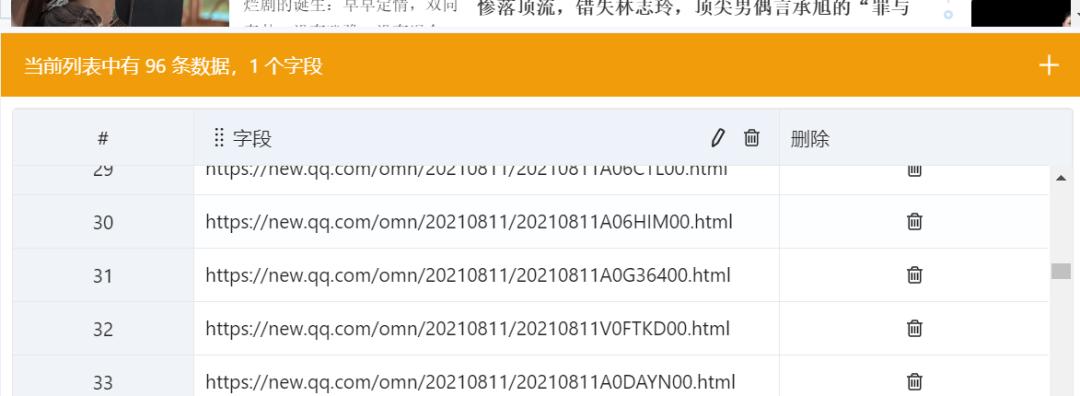
我们接着点击「生成采集设置」:
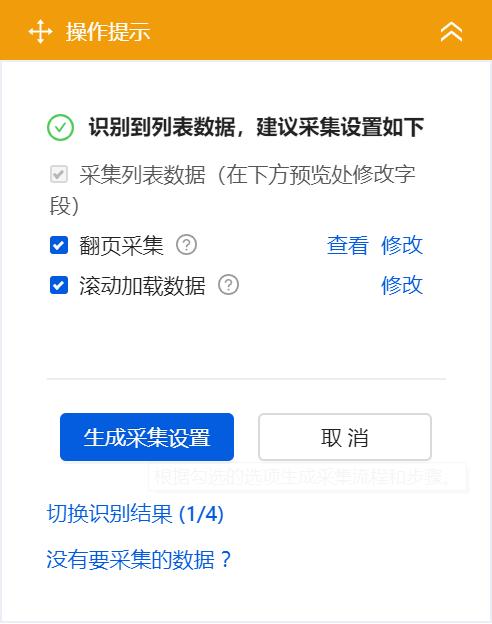
可以进入到下一步的操作中,在这里可以看到八爪鱼的采集流程:

我们直接「保存并开始采集」:
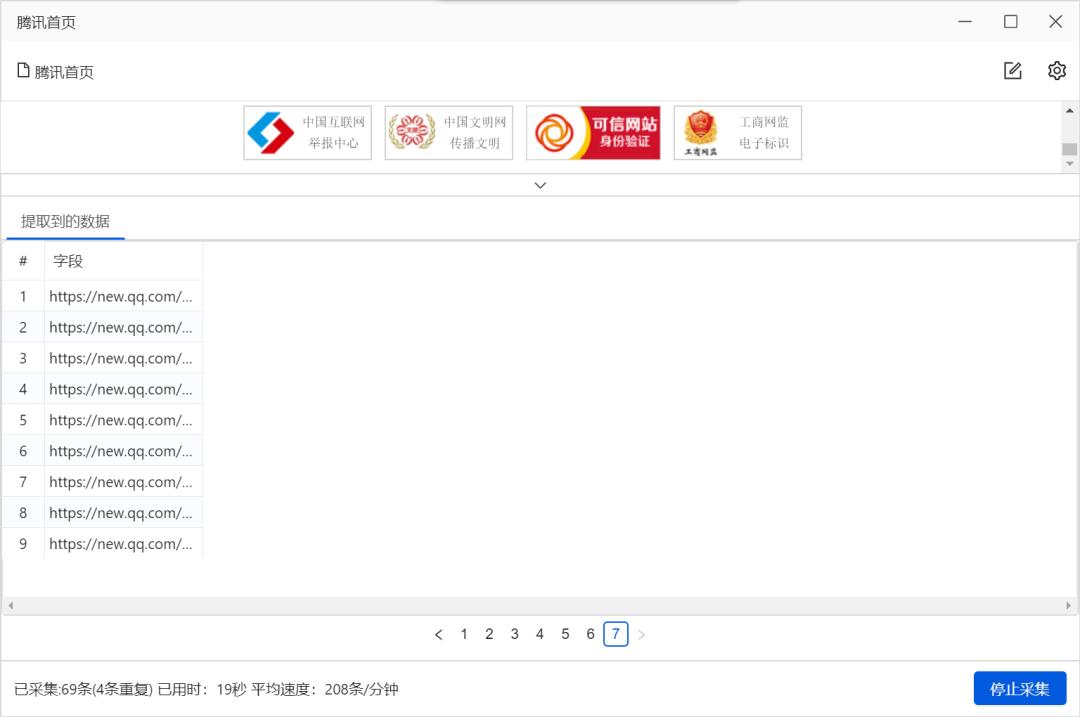
结果出来的还是一个包含 WebView 的窗口,上面是 WebView 打开需要采集的URL,下方是采集的进度和状态。
窗口中不断打开待采集的URL,最终提示采集完成:
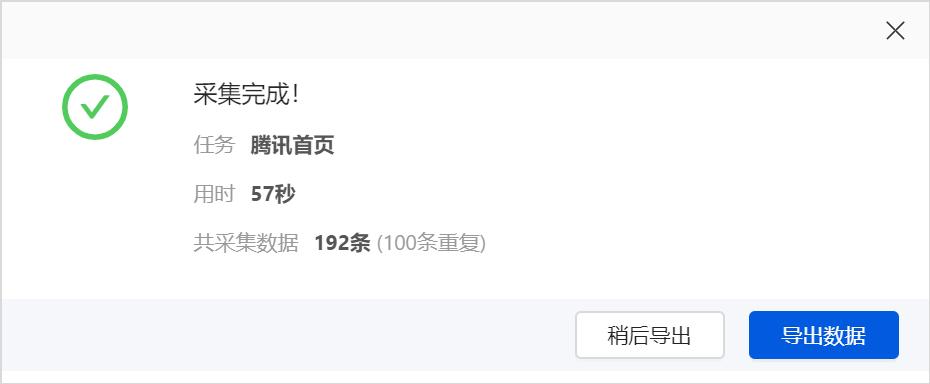
我们导出数据,可以选择导出到本地或是数据库,在这里,我们选择导出本地:
最后导出完成,我们看看实际的效果:

感觉还是不如火车头:
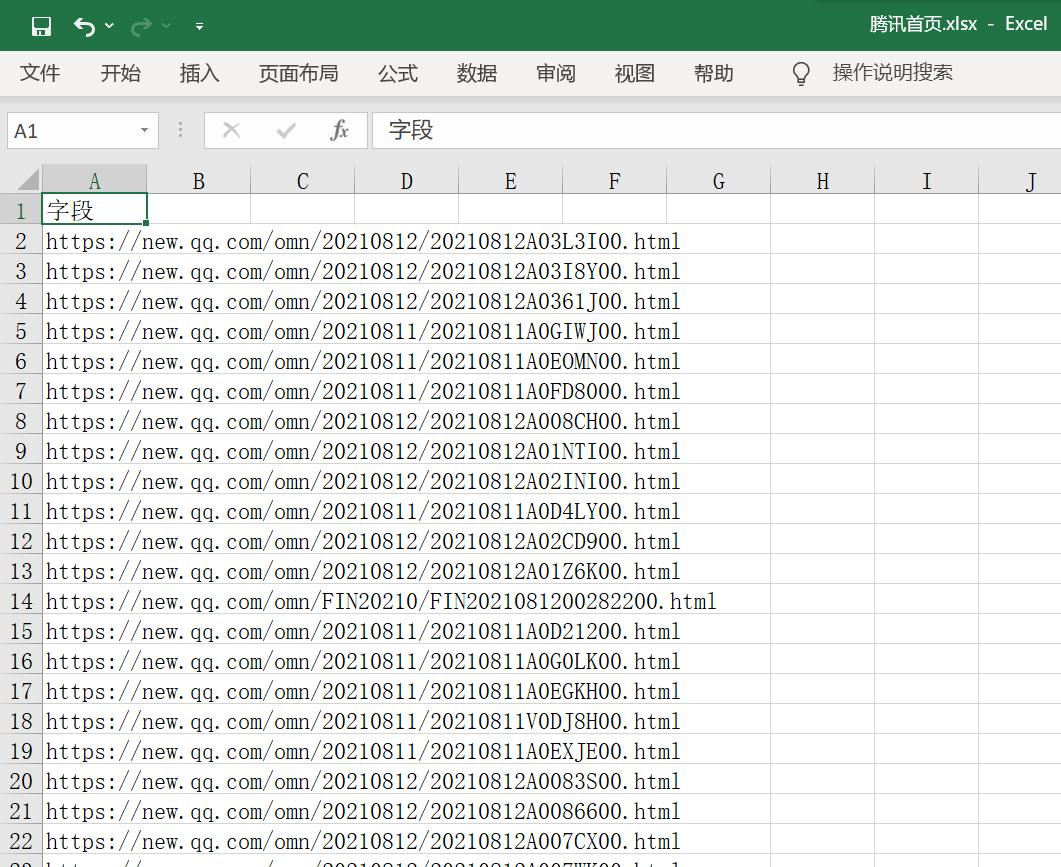
最后
火车头采集器和八爪鱼采集器分别用州的先生博客和腾讯网进行了测试。下面简单进行一下评价吧:
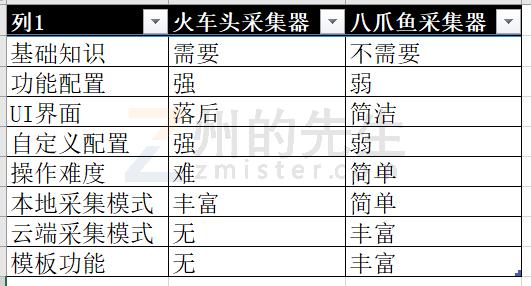
火车头虽然UI界面不友好,配置稍显繁复,但是对州的先生来说,其更加符合个人的使用习惯。
而八爪鱼,看起来使用更加傻瓜化,但是完全依赖于「浏览器自动化操作」:
效率稍微偏低,而且如果不使用模板(模板得升级会员或付费),自己配置出来的采集结果,也很容易一团糟。
与其如此,不如稍微去掌握一点计算机知识,用火车头会更加好。
 微信扫一扫
微信扫一扫